Evaluation of the equation for predicting dry matter intake of lactating dairy cows in the Korean feeding standards for dairy cattle
Article information

Abstract
Objective
This study aimed to validate and evaluate the dry matter (DM) intake prediction model of the Korean feeding standards for dairy cattle (KFSD).
Methods
The KFSD DM intake (DMI) model was developed using a database containing the data from the Journal of Dairy Science from 2006 to 2011 (1,065 observations 287 studies). The development (458 observations from 103 studies) and evaluation databases (168 observations from 74 studies) were constructed from the database. The body weight (kg; BW), metabolic BW (BW0.75, MBW), 4% fat-corrected milk (FCM), forage as a percentage of dietary DM, and the dietary content of nutrients (% DM) were chosen as possible explanatory variables. A random coefficient model with the study as a random variable and a linear model without the random effect was used to select model variables and estimate parameters, respectively, during the model development. The best-fit equation was compared to published equations, and sensitivity analysis of the prediction equation was conducted. The KFSD model was also evaluated using in vivo feeding trial data.
Results
The KFSD DMI equation is 4.103 (±2.994)+0.112 (±0.022)×MBW+0.284 (±0.020) ×FCM−0.119 (±0.028)×neutral detergent fiber (NDF), explaining 47% of the variation in the evaluation dataset with no mean nor slope bias (p>0.05). The root mean square prediction error was 2.70 kg/d, best among the tested equations. The sensitivity analysis showed that the model is the most sensitive to FCM, followed by MBW and NDF. With the in vivo data, the KFSD equation showed slightly higher precision (R2 = 0.39) than the NRC equation (R2 = 0.37), with a mean bias of 1.19 kg and no slope bias (p>0.05).
Conclusion
The KFSD DMI model is suitable for predicting the DMI of lactating dairy cows in practical situations in Korea.
INTRODUCTION
Dry matter intake (DMI) is a major factor determining milk production in lactating dairy cows. Accurate estimation of the DMI is thus important to diet formulation to prevent under- or over-feeding, which is directly related to the health and performance of cows [1] and farm income [2]. Several models for predicting DMI have been proposed worldwide, and similarly, in South Korea, researchers have sought to develop a DMI model that can be used in domestic environments.
The first edition [3] and the first revised edition [4] of the Korean feeding standards for dairy cattle (KFSD) adopted the empirical model presented by NRC [1], which is the most widely used DMI prediction equation for lactating dairy cows. For the second revised edition of the KFSD, the program committee considered developing a new DMI model since the NRC [1] model was based on experimental data from the early 1990s. When evaluated with the latest data, the NRC equation (and other existing DMI equations) showed significant mean and slope biases [5]. Therefore, the second revision of the KFSD included a new empirical DMI prediction model for lactating dairy cows using data from 2006 to 2011 [6]. However, the adequacy of development procedure of the model was not validated. Moreover, the model was not evaluated with in vivo feeding trial data conducted in Korea.
The objectives of this study were i) to describe the development of the DMI prediction model of the KFSD, ii) to evaluate and compare the predictability of the model with several existing DMI equations, and iii) to evaluate the model using in vivo feeding data conducted in a Korean dairy farm.
MATERIALS AND METHODS
Database construction
A literature database based on the research articles published in the Journal of Dairy Science from January 2006 to June 2011 (volumes 89 to 94) was constructed and contained 1,065 treatment means from 287 studies (Table 1). Data were excluded if i) the milk yield (MY) was not reported, ii) the breed was other than Holstein, iii) the DMI as a percentage of body weight (DMIpBW) was less than 2%, iv) the forage as a percentage of dietary dry matter (FpDM) was less than 30% or 100%, v) the dietary neutral detergent fiber (NDF) content in the dry matter (DM) basis was less than 25%, or vi) the week of lactation was missing. Among the studies that met the above criteria, those containing less than four observed means were assigned to the evaluation dataset - four observations were selected to balance the required sample size to estimate the correlations among variables within each study and the number of studies used for developing an equation [7]. The final dataset for developing a DMI equation included 458 observations from 103 studies (Table 2).
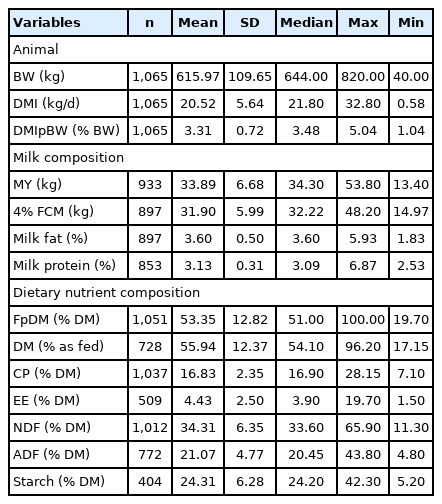
Descriptive statistics of the animal information, milk yield and composition, and the dietary nutrient composition of the data in the literature database
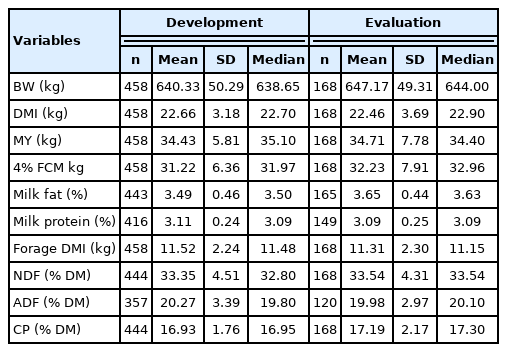
Descriptive statistics of the development and evaluation databases
Model development
The variables that can be routinely measured or calculated in practice were selected as the candidate explanatory variables of DMI (kg/d). These included the animal factors (i.e., body weight [BW, kg], metabolic BW [MBW, kg0.75]), milk production (i.e., MY [kg/d]), and 4% fat-corrected milk yield [FCM, kg/d]) and the dietary components and their intake (i.e., FpDM [%], NDF [% DM], crude protein [CP, % DM], starch [% DM], acid detergent fiber [% DM], CP intake [kg/d], NDF intake [kg/d], starch intake [kg/d], and forage intake [kg/d]). Unlike the 2001 dairy NRC [1], the dietary components were also included because they may limit the intake of lactating dairy cows [8].
The development procedure was divided into two phases. The first phase was to identify the independent variables that were statistically significant for DMI prediction. A random coefficient model with study as the random variable was used via the MIXED procedure in SAS (SAS Institute, Carey, NC, USA). The statistical model in matrix notation is:
where y is the vector of the observed DMI with size N, X is the n×p matrix of xi,j, β is the parameter vector with size p for the fixed effects, Z is the designed N×(s×p) matrix that was blocked diagonally corresponding to each study (ni×p) to account for the random effect of study, N is the total number of observations, s is the number of studies, ni is the number of observations that study i contained, p is the number of parameters, which is one (intercept) plus the number of variables used in the equation, e and u are the vectors of independent, identically and normally distributed random errors (E[u] = 0, Var[u] = G, E[e] = 0, Var[e] = R), G is the (s×p)×(s×p) matrix that contained the variance components in a diagonal structure with a block matrix for each study, and R is σ2IN when IN denotes the N×N identity matrix. Among the acceptable regression models with a linear combination of the significant explanatory variables, the model with the lowest Akaike’s (AIC) and Bayesian information criteria (BIC) was selected.
In the second phase, the parameters of the variables in the best model from phase one were estimated by fitting the model via the general linear model procedure in SAS. Reduced DMI in the early stages of lactation was accounted for by using the equation of Roseler et al [2], who developed a lag function for adjusting the DMI during the first 16 weeks of lactation. The lag function is an exponential function of the current week of lactation and a different value for the month of lactation when peak MY occurs. The Lag[2] assumes peak MY occurs in the second month of lactation and uses a value of 2.36, while Lag[3] uses a value of 3.67 and assumes that peak MY occurs in the third month of lactation. The value calculated by the lag function is a multiplier to the basic DMI equation. The NRC and the Cornell Net Carbohydrate and Protein System (CNCPS) use this function, but with different assumptions for the month of lactation when peak MY occurs. NRC uses Lag[3], while CNCPS uses Lag[2]. The equation developed in this study uses Lag[2]; the peak MY occurred in the second month of lactation in Korea [9]. The lag function used in our model is:
Evaluation and comparison of the KFSD DMI equation
The KFSD equation developed in this study was compared to other published DMI equations using the evaluation dataset. The data in the evaluation dataset did not contain the information for any of the input variables of the tested equations, it was excluded from the evaluation database; the final evaluation database included 168 observations from 74 studies (Table 2). The KFSD DMI equation was compared to the NRC [1], CNCPS [10], and the Japanese feeding standard (JFS) [11] model (Table 3). To evaluate the NRC and CNCPS equations, the base equations with different lag equations were also examined (i.e., NRC with Lag[2], NRC with Lag[3], CNCP with Lag[2], and CNCPS with Lag[3]). The JFS DMI equation was included because it is one of the most recently developed empirical equations. Other previously published DMI equations [2,12–14] were not included because initial comparisons indicated that the NRC and CNCPS models were superior [5]. The coefficient of determination (R2) and root mean square prediction error (RMSPE) were used as indicators of the model precision and accuracy, respectively. Residual analyses were also conducted to assess the mean and slope biases of the models.

Published prediction equations of the dry matter intake (DMI, kg/d) of lactating dairy cows compared to the developed KFSD DMI equation
Sensitivity analysis
A sensitivity analysis of the DMI prediction equation to input variables was conducted in @Risk version 7.0 (Palisade Corp., Newfield, NY, USA). The distribution of the input variables was generated from a data set of 629 observations of lactating dairy cows from the development and evaluation datasets. Probability distributions were fit to the data for each variable in @Risk, and the best distribution was selected by comparing three different fit statistics (χ2, Kolmogorov-Smirnov, and Anderson-Darling values). The data were assumed to be normally distributed if all three goodness-of-fit tests failed to reject the null hypothesis; otherwise, a probability distribution, which showed the best fit among the three tests (based on ranking), was chosen. Simulations were performed to obtain the distribution of the predicted DMI in @Risk, and the input variables needed to predict DMI were sampled from each distribution using the Latin hypercube method. The iterations of the simulation were continued until <1% convergence was achieved for a DMI distribution. The sensitivity of the DMI equation to the input variables was analyzed by regression analysis in @Risk, and the coefficients from a standardized regression were used to rank the relative importance of the input variables.
Evaluation of the KFSD DMI equation with in vivo feeding trials
The predictive power and accuracy of the KFSD DMI equation for lactating dairy cows were evaluated using in vivo experimental data. The data were collected from November 2016 to June 2017 from a research dairy farm for the National Institute of Animal Science in Chungcheong Province, Republic of Korea. All animal usage and experimental procedures were conducted with the approval of the Institutional Animal Care and Use Committee at the National Institute of Animal Science, Rural Development Administration, Republic of Korea (Approval number: 2016-173) in 2016. The study used 32 Holstein lactating cows (746±75.1 kg), and the average parity of the cows was 2.1±1.00 (11 primiparous and 21 multiparous). The cows were housed together in a bedded pack barn with wood shavings, equipped with an automatic milking system (Astronaut 3, Lely, Wageningen, Netherlands). The cows were fed total mixed rations (TMR) ad libitum, provided twice daily at 09:00 and 17:00, and their individual daily intakes were recorded by an automatic feeding system with radio frequency identification (Dawoon Co., Incheon, Korea). The intake and MY data were collected from the automatic milking system, and the nutrient composition of the TMR and the concentrate mix are described in Table 4. Feed samples were analyzed for proximate constituents and fiber fractions as per AOAC [15] and Van Soest et al [16], respectively. Milk samples were collected from each cow once a week (in triplicate) to analyze the fat and protein contents via infrared spectroscopy (MilkoScan 4000; Foss Electric, Hillerød, Denmark).
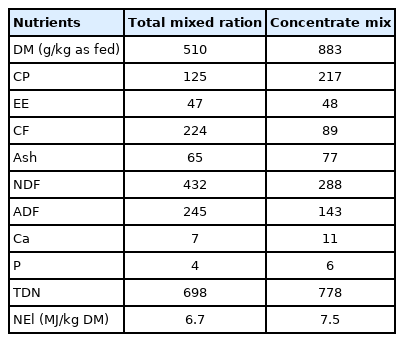
Nutrient composition (g/kg DM or as stated) of the total mixed ration and concentrate mix used in the feeding trial with lactating Holstein cows
The entire data set contained individual intake and milk production data for seven months, but the data for February was removed due to problems with data collection. The average and standard deviation for each individual and parameter was calculated; observations greater or less than three times the standard deviation were excluded as outliers. The weekly and monthly averages for each individual and parameter were also calculated, and the database included 673 weekly and 173 monthly observations. The descriptive statistics for the monthly observations are provided in Table 5, and this dataset was used to evaluate the model. Model evaluation was also performed by categorizing the data set into cold (November to January) and warm (March to June) seasons. The model was compared to the NRC (2001) equation [1], which has shown higher predictive power than the other published models. R2 and RMSPE were used as indicators of model precision and accuracy, respectively, and residual analyses were conducted to assess the mean and slope biases of the models.
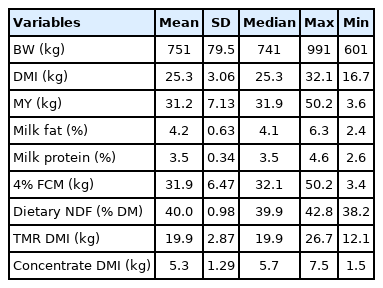
Descriptive statistics of the feeding trial data used to evaluate the DMI prediction equation
RESULTS AND DISCUSSION
Development of the KFSD DMI equation
In the first phase, a linear combination of MBW, FCM, and NDF was the best-fitting model among all of the possible linear combinations of the candidate variables (data not shown). As indicated by the values (means and standard deviations) in Table 2, these equations cover a wide range of production situations. The parameters of MBW, FCM, and NDF were estimated using ordinary least squares as follows:
where MBW is the metabolic body weight (kg, BW0.75), FCM is the 4% fat-corrected milk (kg/d), and NDF is the NDF content in the dietary DM (%DM).
The nutritional requirements are fundamentally determined by body weight [17], so many DMI prediction models have included BW [5,10,18,19]. MBW, defined as the three-fourth power of body weight, has also been frequently used in previously published models [1,11,13]. In this study, MBW was a more appropriate variable to predict DMI than BW (data not shown). Other studies have also found that models including MBW exhibit better accuracy and lower prediction error than models including BW [20]. Feed intake is determined by the energy requirements [21], which, in lactating dairy cows, can be divided into the requirements for maintenance and milk production. The maintenance requirements are proportional to the MBW, indicating the amount of active tissue or metabolic mass [22], so MBW is more likely to act as a reliable variable in the DMI prediction model.
The feed intake of lactating cows is positively correlated with milk production [23], suggesting that increased milk production leads to an increase in DMI. Thus, several prior studies have used MY or FCM as an input variable in the DMI prediction model for lactating cows. The results of this study show that FCM is a more suitable variable to predict DMI than MY (data not shown). FCM with MY adjusted to 4% fat was consistently included in models more often than MY [6,11,12,18,24], and the energy required for lactation is proportional to FCM [25]. Therefore, FCM may improve the predictive power of the DMI prediction model.
The only dietary factor included in our final equation was NDF. The NDF content of the feed is a reliable predictor of DMI due to its strong correlation with DMI [26]; there is a positive correlation between NDF and rumen fill, and a negative correlation between NDF and energy density [18]. NDF has low digestibility and negatively affects DMI by increasing the rumen residence time and physical satiety. Previous studies found that when the NDF content of the feed was more than 25%, the intake reduced due to rumen filling, but when the NDF content was less than 25%, the intake decreased due to metabolic feedback [2,8,19]. Feed intake is also affected by the bulk density, digestion rate, time spent ruminating and chewing, and the disappearance rate of the feed [27], all of which are strongly correlated with the NDF content. Thus, NDF has often been included in the DMI prediction equations [13,14,28].
Evaluation of the KFSD DMI equation with an independent dataset
Table 6 summarizes the statistics from the regression analyses of the KFSD DMI equation and the previously published models when evaluated with the evaluation data set. The precision of the models (R2) was similar (0.46 to 0.48), except for the JFS model (R2 = 0.44). The R2 value of the regression of the observed and predicted values is widely used as a precision index when the relationship is linear. The RMSPE value represents the average vertical distance of each point to the predicted value in a residual plot and measures how well the predictions fit the observed data. It is a common, reliable estimate of the predictive accuracy of a model. The KFSD equation had the lowest RMSPE value (2.7 kg) among the previously published models (Table 6), and the KFSD DMI predictive model reduced RMSPE by a minimum of 0.1 and a maximum of 0.98 compared to other models.
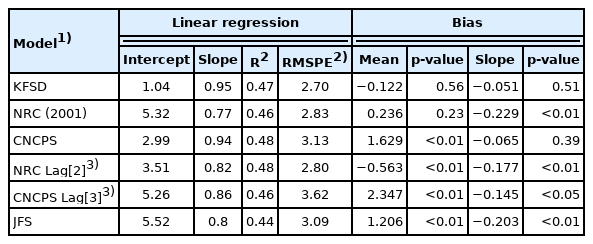
The predictive precision and accuracy of the KFSD DMI equation and other published equations
Figure 1 shows plots of the observed and residual DMI values (observed minus predicted DMI) versus the predicted DMI values from a model (using the evaluation dataset). When the residual values are regressed on the predicted values that are centered on the mean predicted value, the regression slope and intercepts represent linear and mean biases, respectively [29]. As shown in Table 6 and Figure 1, the intercept and slope of the regression did not differ from 0, indicating that the KFSD equation is unbiased (p>0.05). However, the other models showed statistically significant mean biases (−0.563 to 2.347, p<0.01), except for the NRC (2001) equation. The slope biases were statistically significant, except for the CNCPS model (−0.065 to −0.203, p<0.05). Therefore, the precision, accuracy, and biases assessments suggest that the KFSD DMI prediction model is better than the other tested models.

Plots of the observed (upper; ●) and residual DMI (observed minus predicted DMI, lower; ○) versus the model-predicted DMI (n = 168). The regression equation was DMI = 0.95×predicted DMI+1.04 (R2 = 0.47, RMSPE = 2.70 kg/d). For the residual analysis, the predicted DMI was centered around the mean predicted DMI before the observed minus predicted (residual) DMI were regressed on the predicted values. The regression equation was residual DMI = −0.122(±0.2091)−0.051(±0.0781)×(predicted DMI−22.5480). DMI, dry matter intake; RMSPE, root mean square prediction error.
The tornado graphs in Figure 2 show the sensitivities of the predicted DMI outputs to the input variables. The standardized regression coefficients indicate the relative importance of the variables and suggest that a one-unit increase in the variable would increase the DMI by one unit (i.e., kg). In the developed KFSD model, the regression coefficient of FCM (0.9) was positive and twice that of the other variables. NDF, the only variable that was negatively correlated with DMI, had a regression coefficient of −0.2, indicating that a 1% p increase in dietary NDF (%) would decrease 0.2 kg of DMI.
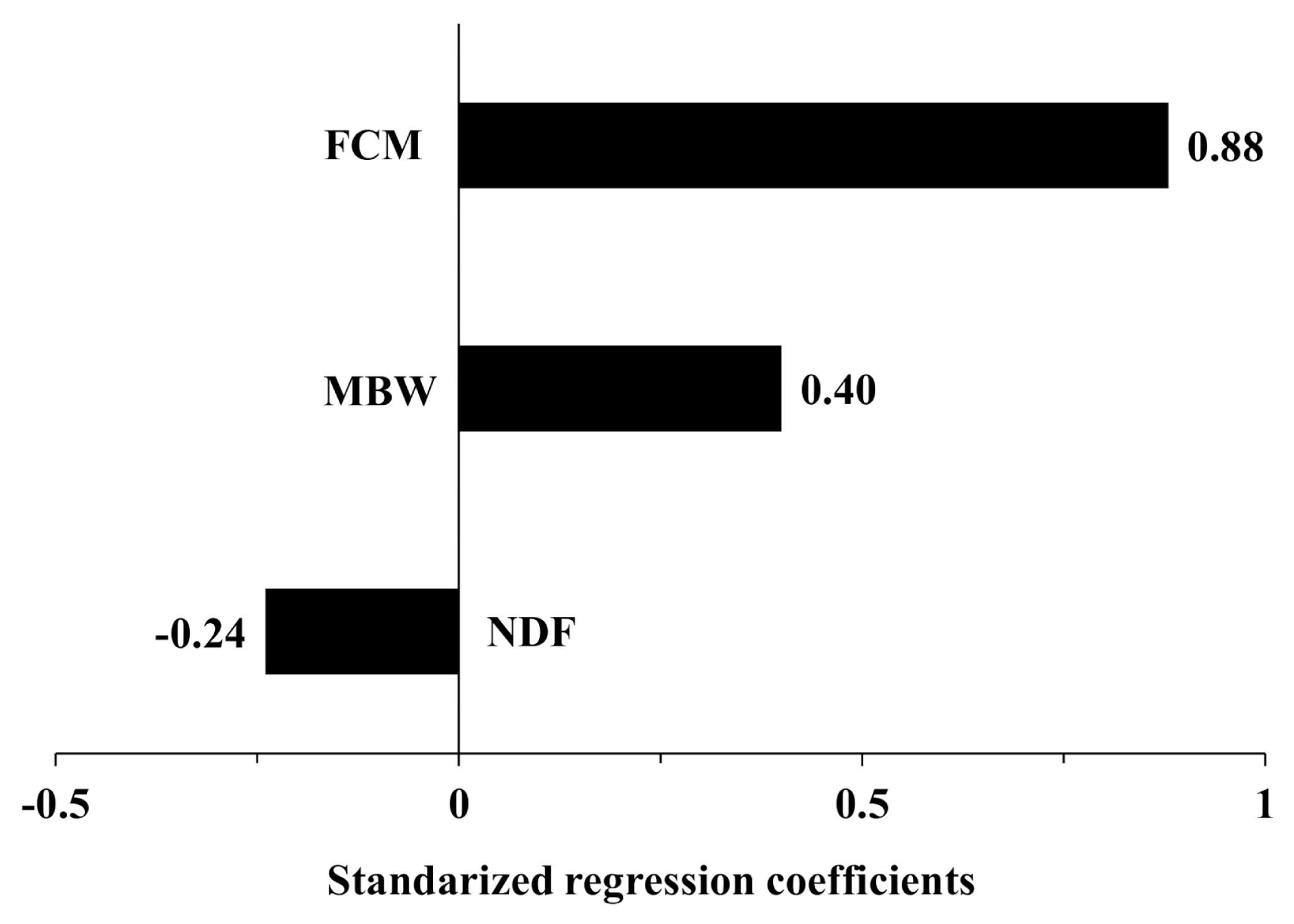
Tornado plot of the standardized regression coefficients for the model inputs. The inputs were ranked based on their standard regression coefficient as the most influential in predicting dry matter intake of the lactating dairy cattle with the Korean feeding standards for dairy cattle (KFSD) equation. FCM is the 4% fat-corrected milk yield (kg), MBW is the metabolic body weight (kg0.75), and NDF is the dietary neutral detergent fiber content (% DM).
Evaluation of the KFSD DMI equation using data from Korean dairy farms
The evaluation results for the KFSD model and the NRC model using in vivo experimental data from a Korean dairy farm are shown in Figure 3 and Table 7. The KFSD model had slightly lower accuracy (RMSPE = 2.71) than the NRC model, but slightly higher precision (R2 = 0.39). The KFSD prediction model had no slope bias (0.03; p>0.05), but it had a significant mean bias (1.2 kg; p<0.01). The NRC model had a significant mean bias (0.41 kg; p<0.05), and the slope tended to bias (−0.16; p = 0.06).
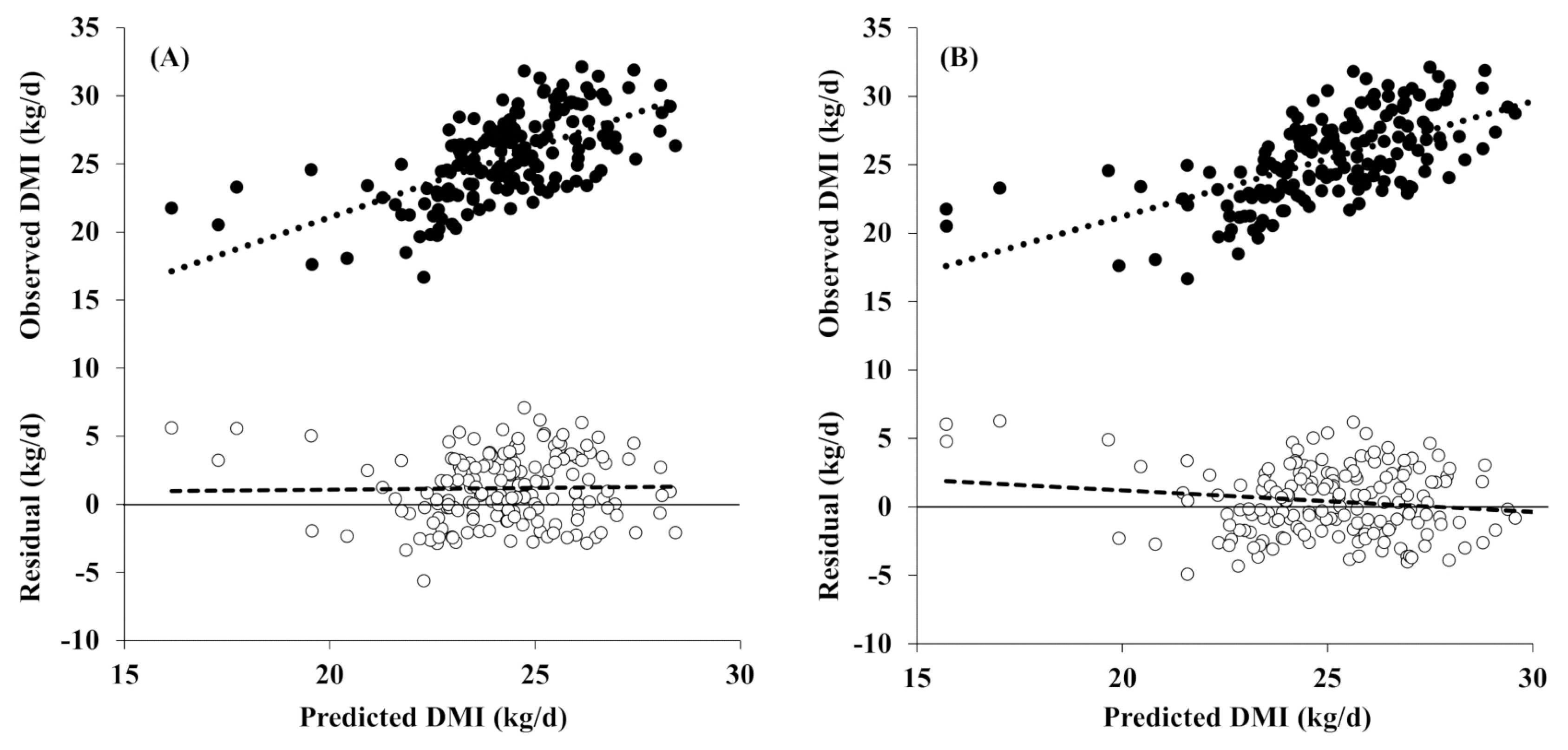
Plots of the observed (upper; ●) and residual DMI (observed minus predicted DMI, lower; ○) versus the model-predicted DMI of (A) the KFSD equation and (B) the NRC equation (n = 173). The regression equations were: (A) observed DMI = 1.03×predicted DMI+0.52 (R2 = 0.39) and (B) observed DMI = 0.84×predicted DMI+4.35 (R2 = 0.37). For the residual analysis, the predicted DMI was centered around the mean predicted DMI before the observed minus predicted (residual) DMI were regressed on the predicted values. The regression equations were: (A) residual DMI = 1.187(±0.1866)+0.028(±0.0993)×(predicted DMI−24.2674) and (B) residual DMI = 0.414(±0.1889)−0.157(±0.0841)×(predicted DMI−25.0406).

The predictive precision and accuracy of the KFSD DMI and NRC (2001) equations
The significant mean bias of the KFSD equation may be because it underpredicts the DMI of lactating cows during the cold season. We reanalyzed the predictive power of the KFSD equation using data from the cold season (November to January); R2 and RMSPE were 0.46 and 3.1, respectively, with no slope bias (p>0.05) but a significant (p<0.001) mean bias (2.34 kg) (Table 7). In contrast, neither the mean nor the slope biases were significant when evaluated with the warm season data (March to June), and the R2 and RMSPE values were 0.37 and 2.43, respectively. With the warm season data, the NRC (2001) equation was not significantly biased (similar to the KFSD equation), but with the cold season data, both the mean and slope were significantly biased (p< 0.05). These results indicate a structural error in predicting the DMI of lactating cows in Korea during the cold season.
The KFSD equation predicted a DMI of ~2.3 kg less than the actual value in the cold season because it seems to have not considered the effect of temperature. In general, when the temperature decreases, the feed intake increases to compensate for the increased energy requirements of maintaining body temperature [30]. The KFSD equation corrects the intake according to the environmental temperature (not proposed in this paper), but this was not considered here because the experimental data lacked information on temperature, humidity, and wind speed. The equation including the environmental module predicts a DMI increase of 9.7% in lactating cows when the monthly average temperature is −10°C (data not shown). The average intake in the evaluation data set was 25.3 kg, and the increased DMI at −10°C was ~2.3 kg, which is similar to the mean bias calculated for the winter data.
In conclusion, the KFSD DMI prediction equation can predict the DMI of lactating cows in Korea with relatively good precision (R2 = 0.35 to 0.47; no structural biases were observed). The KFSD equation has a relatively high predictive power compared to the other previously published equations, including the prediction equation of the NRC (2001) [1]. However, the KFSD equation may underpredict DMI in the cold season by approximately 2.3 kg. If the DMI increase at low temperatures is evaluated with the environmental module, then the mean bias may be significantly reduced.
Notes
CONFLICT OF INTEREST
We certify that there is no conflict of interest with any financial organization regarding the material discussed in the manuscript.
ACKNOWLEDGMENTS
This research was supported by the Rural Development Administration, Republic of Korea (Project No. PJ0150482021).