



INTRODUCTION
Three types of genetic variations exist in the genome. The largest type is microscopic structural variation, which can be detected by optical microscopy; these include aneuploidies and variation in chromosome size (Reich et al. 2002). The most common and smallest type is single nucleotide polymorphisms (SNPs) (Sachidanandam et al., 2001), detected at the single nucleotide level. Between microscopic structural variation and SNPs, the mid-size variations are submicroscopic variants, such as deletions, duplications and insertions, which are termed copy number variations (CNVs) (Scherer et al., 2007). Usually, CNVs are defined as DNA segments of >1 kb that show copy number differences in comparison with a reference genome, and they have been proposed to exclude insertion/deletions of <1 kb (ŌĆśindelsŌĆÖ) (Scherer et al., 2007; Henrichsen et al., 2009a; Alvarez and Akey, 2012), although recent studies have suggested that an indel/CNV cutoff of 50 bp is preferable (Alkan et al., 2011; Mills et al., 2011). These CNVs, so called unbalanced structural variants (SVs) (Mills et al., 2011) are important genetic factors for studying human diseases and may have as large of an effect on phenotype as SNPs (Feuk et al., 2006; Sharp et al., 2006). It has been widely accepted that CNVs are involved in differential disease susceptibility (Hollox et al., 2003; Aldred et al., 2005; Gonzalez et al., 2005; Aitman et al., 2006).
At the genome-wide scale, the functional impact of CNVs has been studied in mouse and rat (Guryev et al., 2008; Henrichsen et al., 2009b; Orozco et al., 2009). In mouse, one study reported that the expression of genes within CNVs show moderate correlations with copy number changes (Henrichsen et al., 2009b), and another study reported that 83% of genes within CNVs were differentially expressed (Orozco et al., 2009). In rat, CNVs show functional relationships with 22 expression quantitative loci (Guryev et al., 2008).
A recent study reported 2,368 CNVs in horse (Doan et al., 2012). However, the relationships between CNVs and gene expression levels in horse have not yet been examined. In the current study, we investigated the effects of copy number deletion in the blood and muscle transcriptomes of Thoroughbred racing horses.
MATERIALS AND METHODS
RNA-seq data before and after exercise
We used RNA-seq data from four horses before and after exercise, as described elsewhere (Park et al., 2012; Kim et al., 2013); the data were submitted to the NCBI Gene Expression Omnibus (GEO) (http://www.ncbi.nlm.nih.gov/geo/) under accession number GSE37870. Briefly, samples of skeletal muscle and blood were taken from Thoroughbred horses before and after exercise. Then, using the Iluumina HiSeq2000, 20 sets of transcriptome data were generated for muscle and blood from four horses both before and after exercise.
The sequences were mapped to a horse reference genome using TopHat (ver.1.4.1) and annotated using the EquCab2 database (http://hgdownload.cse.ucsc.edu/downloads.html-horse) (Supplementary Table 3).
Mapped reads were assembled using Cufflinks (ver.1.3.0) (Trapnell et al., 2010) to estimate the abundance of genes. Fragments per kilobase of exon per million fragments (FPKM) of each sample were calculated to estimate the expression levels of the genes. The FPKM value set for all genes in the muscle and blood tissue samples was normalized using Quantile normalization (Bolstad).
Analysis of horse DNA re-sequencing data
Whole-blood samples were collected from the same four Thoroughbred racing horses used in RNA-seq analysis. Blood (10 mL) was drawn from the carotid artery and treated with heparin to prevent clotting. ManufacturersŌĆÖ instructions were followed to create a paired library. The 90-bp pair-end reads sequence data were generated using HiSeq 2000 (Illumina, Inc., San Diego, CA, USA). Using Bowtie2 (ver. 2.1.0) (Langmead and Salzberg, 2012) with the default settings, pair-end sequence reads were mapped to the reference horse genome (equCab2). We used the following open-source software packages: Picard Tools (ver. 1.75), SAMtools (ver. 0.1.18) (Li et al., 2009), and the genome analysis toolkit (GATK) (version 2.2.4) (McKenna et al., 2010) for downstream processing and variant calling (Supplementary Figure 6).
The DNA re-sequencing data of 14 Thoroughbred racing stallions were downloaded from the NCBI sequence read archive (SRA) database under accession number SRA053569 described elsewhere (Kim et al., 2013). The pair-end sequence reads data were generated by the Korean Racing Authority, and the sampling, sequencing and mapping procedure were same as described above. The sequencing data of all 18 Thoroughbred racing horses are summarized in Supplementary Table 5.
Copy number variation identification for four Thoroughbred horses
We extracted CNVs of the four Thoroughbred racing horses used in RNA sequencing from the aligned re-sequencing data of the combined eighteen horses. The CNV extraction tool, Genome STRUCTURE In Populations (GenomeSTRiP) (ver. 1.04) (Handsaker et al., 2011) was used to acquire deletion calls of CNVs using the program default options. Each variant was genotyped, and the genotype quality was assessed based on the measurement of genotype likelihoods. To consider highly plausible variants, CNVs that passed the genotype quality threshold for all eighteen samples were selected as CNVs of four Thoroughbred horses involved in RNA sequencing. We then excluded two-allele deletion CNVs of which associated gene had certain expression level.
Copy number variations and gene expression analysis
To analyze the relationship between CNVs and gene expression, CNVs and genes were linked according to their start-end position information from GenomeSTRiP and the EquCab2reference annotation database. The linear regression slope between the gene expressions and the deletion status of CNVs was estimated using the ŌĆśRŌĆÖ statistics package (Hornik, 2011). The genes that showed consistent tendency in gene expressionŌĆōCNV slope under all four conditions (blood and skeletal muscle, before and after exercise) were selected to obtain functional information. The equine Ensembl gene IDs were converted to official gene symbols by cross matching with human Ensembl gene IDs and the official gene symbols. The official gene symbols of human homologs of equine genes were used for KEGG pathway annotation and KEGG pathway enrichment analyses using the Database for Annotation, Visualization and Integrated Discovery (DAVID) (Dennis Jr et al., 2003). For the genes that show consistent tendency, the representation of functional groups in blood and skeletal muscle relative to the whole genome was investigated using the Expression Analysis Systematic Explorer (EASE) tool (Hosack et al., 2003) within DAVID, of which the EASE is a modified FisherŌĆÖs exact test used to measure enrichment of gene ontology terms (Alterovitz and Ramoni, 2010).
Copy number variation validation
Genomic DNA samples from each horse were assessed by polymerase chain reaction (PCR) to validate the CNV region selected by GenomeSTRiP. Twenty-six CNV regions of an appropriate size (up to 2.5 kb) for PCR, were selected randomly. All primer pairs listed in Supplementary Table 4 were designed to cover extracted CNV regions. The PCR amplification was carried out using a 2├Ś PCR master mix (iNtRON BioTechnology, Seongnam, Gyeonggi, Korea) containing 1 pM of each primer set. Amplification was performed as follows: 1 cycle of 95┬░C for 5 min; 35 cycles of 95┬░C for 30 s, annealing at the temperature (Supplementary Table 4) for 20 s, and 72┬░C for 1 min or 1 min 40 s (for CNV lengths <1 kb or >1 kb, respectively), followed by 1 cycle of 72┬░C for 10 min. All amplicons were separated on a 1% ethidium bromide stained gel for 20 min.
RESULTS
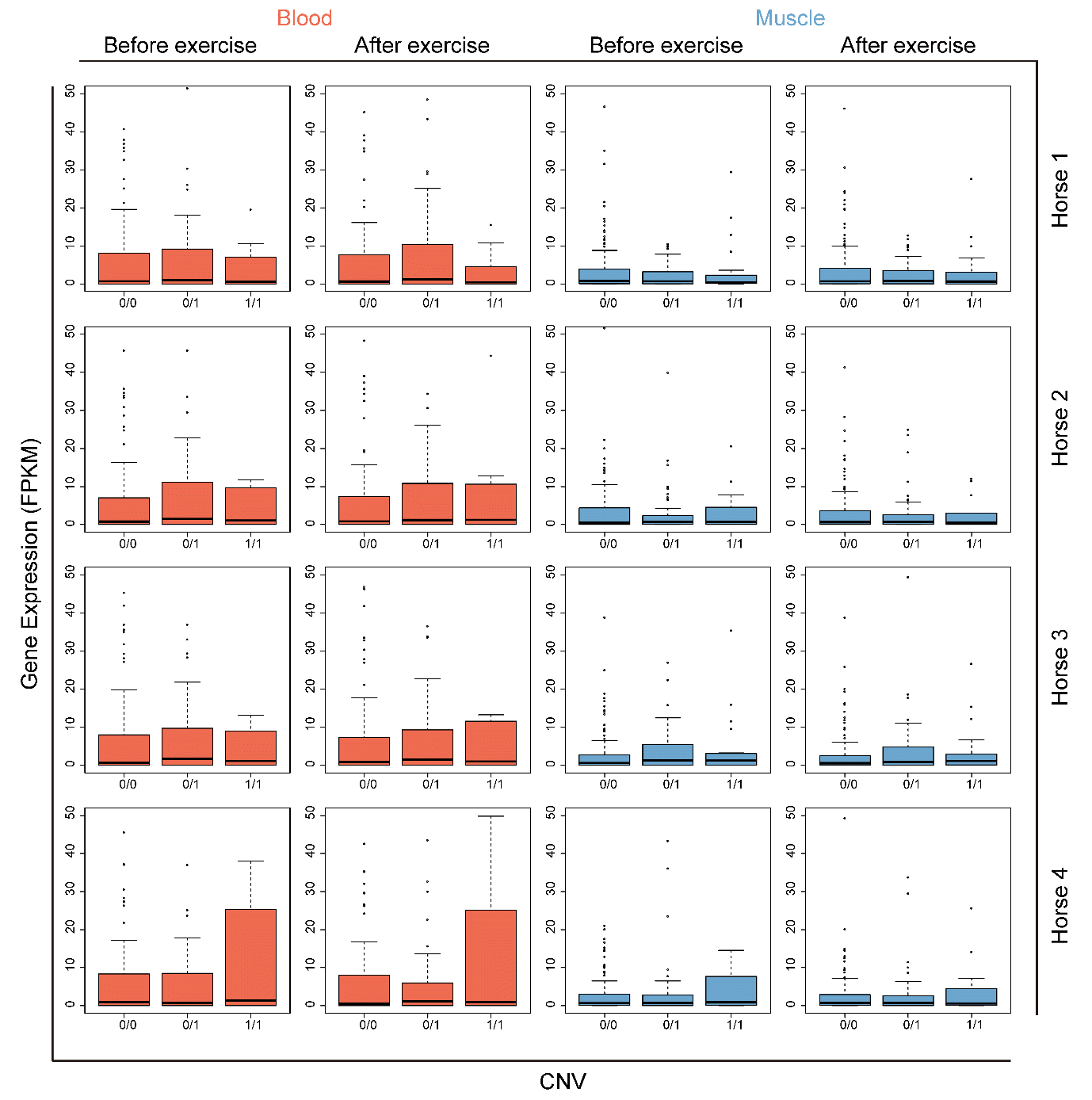
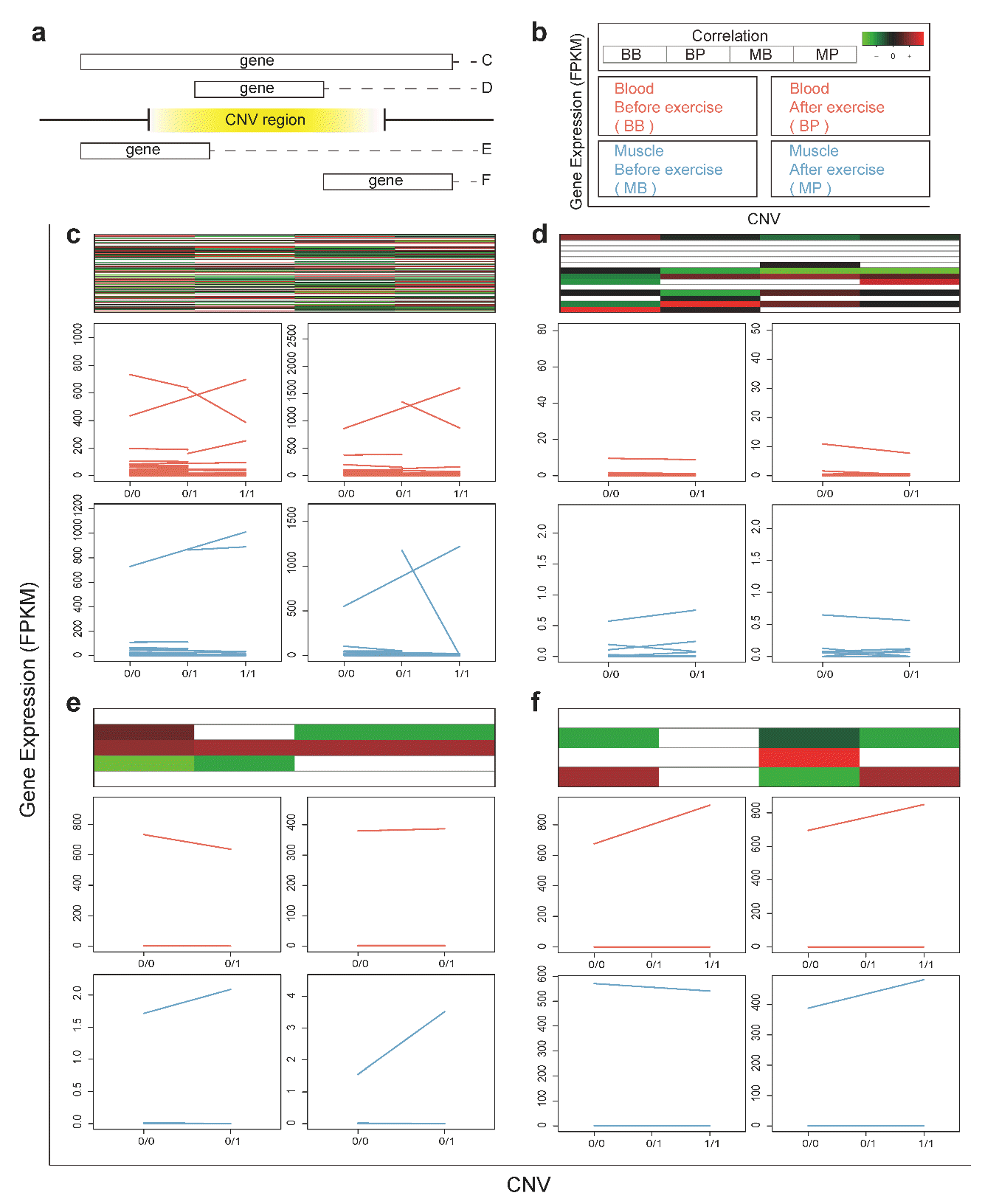
We identified 2,648 possible CNVs from 10,094 CNV candidates using GenomeSTRiP (Handsaker et al., 2011). We retained 1,246 CNVs of deletion calls after applying the genotype quality threshold for further analysis. These plausible CNVs of deletion polymorphisms were linked to the gene expression profiles of four Thoroughbred horses depending on their start-end position. There were four possible position classifications: ŌĆścoverŌĆÖ indicates that the genes cover CNV regions, ŌĆśinsideŌĆÖ indicates that the genes are located in CNV regions, ŌĆśfrontŌĆÖ indicates that the genes span the front part of the CNV regions, and ŌĆśrearŌĆÖ indicates that the genes span the rear part of the CNV regions (Figure 2a). Genes not expressed in all four conditions (i.e., blood and skeletal muscle, before and after exercise) were removed from the expression profiles of the four Thoroughbred horses. Finally, we obtained a total of 252 pairs of CNVs and associated genes, including 229 pairs in the ŌĆścoverŌĆÖ group, 14 in the ŌĆśinsideŌĆÖ group, 5 in the ŌĆśfrontŌĆÖ group, and 4 in the ŌĆśrearŌĆÖ group.
For each pair of CNVs and associated genes in the skeletal Box-and-Whisker plot was used to display the relationship between CNV status and its position-linked gene expression levels. Figure 1 and Supplementary Figure 2 to 4 depict the relationship between CNVs and gene expression in the ŌĆścoverŌĆÖ, ŌĆśinsideŌĆÖ, ŌĆśfrontŌĆÖ and ŌĆśrearŌĆÖ groups. The deletion status of CNVs was denoted by 0/0 for no deletion at the population- or individual-based CNV region, 0/1 for one allele deletion at the CNV region, or 1/1 for two allele deletions at the CNV region. From the plots, we observed only a reduced gene expression pattern according to allele deletion in the blood of the ŌĆśinsideŌĆÖ group. For the other groups, we observed no common tendency of positive or negative correlation patterns between the deletion status of CNVs and gene expression levels in blood and muscle before and after exercise.
The linear regression slope was estimated for each pair of CNVs and associated genes to examine the relationship between gene expression level and CNV deletion status individually. Supplementary Figure 1a displays the PAK7 gene expressions of the four horses (sampled in blood before exercise) and their linked CNV region deletion status, showing a pattern of decreased expression with an increasing number of allele deletions. In contrast, Supplementary Figure 1b presents the HLA-DQB1 gene (DQB gene in horse) expression levels of the four horses (sampled in blood before exercise) and their linked CNV region deletion status, showing a pattern of increased expression with an increasing number of allele deletions.
For the entire trend of increased or decreased gene expression level according to CNV deletion status, the linear regression lines in all four conditions are shown in Figure 2(c, d, e, and f) and the linear regression results in Supplementary Table 1. In all position-related groups and sampling conditions, the linear regression results did not show a clear consistent positive or negative relationship between CNV deletion status and gene expression levels in blood and muscle before and after exercise.
In Supplementary Table 1, the number of positive and negative slope groups indicted no significant difference between the numbers of the positive and negative slope groups at each condition using a paired sample t-test (p = 0.692).
For the genes that showed a consistent tendency in the four sampling conditions, human HGNC (Human genome organisation Gene Nomenclature Committee) symbols were annotated using the Ensembl orthologous information, and using the human HGNC symbols, those involved in KEGG pathways were identified (Supplementary Table 2). Among them, 15 genes showed decreased expression patterns when the allele deletion occurred at CNVs in the ŌĆścoverŌĆÖ group and in all four sampling conditions (cover negative), and 12 genes show increased expression patterns when the allele deletion occurred at CNVs in the ŌĆścoverŌĆÖ group (cover positive). Only one gene showed decreased expression when the allele deletion occurred at a CNV region in the ŌĆśinsideŌĆÖ group (inside negative). In ŌĆścover negativeŌĆÖ, the KEGG pathway term ŌĆścell adhesion moleculesŌĆÖŌĆöwhich includes CNTN1 and PTPRM genes wasŌĆöenriched.
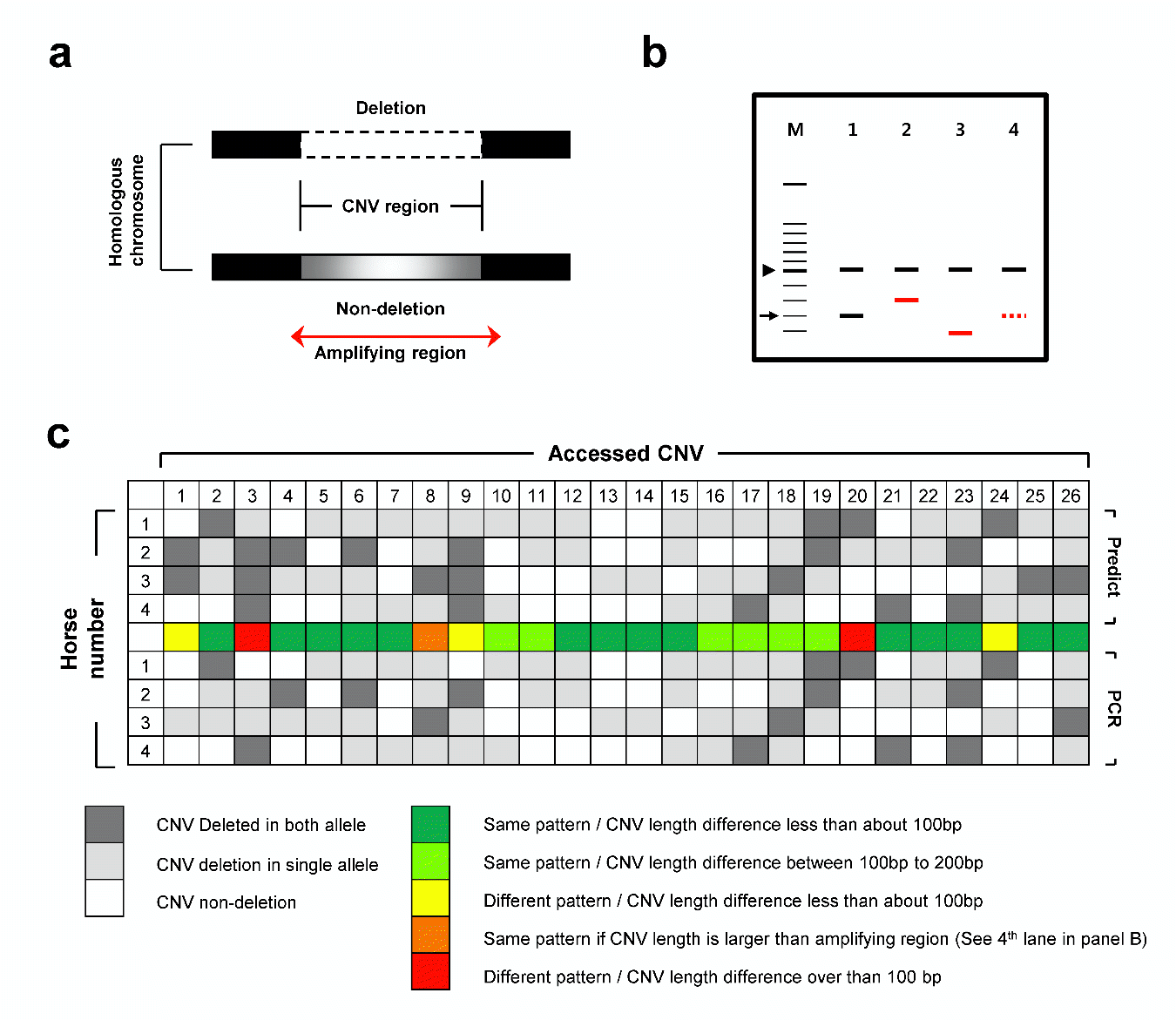
To confirm that the extracted CNV region is genuine, we performed genomic DNA PCR with CNV region-spanning primer sets (Figure 3a and Supplementary Table 4). Among the extracted CNV regions that were of appropriate size for PCR (<2.5 kb), 26 CNV regions were selected randomly and the CNV deletion type and length in each was examined (Supplementary Figure 5). The amplicons in the deleted allele in the CNV region were of three sizes in comparison to the prediction by GenomeSTRiP: i) similar size of amplicon in the deleted allele in the CNV region (Figure 3b, lane 1), ii) 100 to 200 bp difference in the deleted allele (Figure 3b, lanes 2 and 3), and iii) absence of amplicon (Figure 3b, lane 4). The amplicon size differences might be due to the genuine CNV region length being shorter (second case) or longer (third case) than that predicted by GenomeSTRiP. Then, the distribution of CNV-deleted or -non-deleted alleles in each individual by PCR was compared to the expected model. By combining the criteria of ŌĆśdeleted amplicon sizeŌĆÖ and ŌĆśdistribution of CNV in each individualŌĆÖ, we evaluated the extracted CNV region as proper or non-proper according to five classifications (Figure 3c): same pattern and CNV length difference <100 bp (green box) or 100 to 200 bp difference (yellow-green box); different pattern but <100 bp CNV length difference (yellow box); same pattern but the CNV was larger than the amplifying region (orange box, CNV8), or both the CNV distribution and amplicon size did not match those expected (red box). We considered that the PCR result showing the same CNV distribution pattern and <200 bp difference in the amplicon of the deleted allele (green and yellow-green boxes) was the proper CNV region. According to this standard, the validation process indicated that the extracting CNV region had 76.92% accuracy (Figure 3c, 20 proper CNV regions of 26 CNV regions examined).
DISCUSSION
In a recent study, 2,368 CNVs were identified using array-based methods (Doan et al., 2012). In the current study, 1,246 CNVs of deletion calls were identified using DNA re-sequencing data from 18 Thoroughbred racing horses. Because we used a different approach to identify CNVs based on re-sequencing data, there could be a difference by platform. Also, the caveat of this approach with the GenomeSTRiP algorithm is that it detects only CNVs of deletions, excluding detection of CNV duplication calls.
We might expect that transcription start sites are located near the start position of genes. In cases of ŌĆścoverŌĆÖ (the genes cover CNV regions) and ŌĆśfrontŌĆÖ (the genes span the front part of the CNV regions), these CNVs will not affect the transcription start site of the position-linked genes, but will affect the gene contents. Thus, cover and front CNVs are expected to affect only a small portion of position-linked gene expression variation. However, in the cases of ŌĆśinsideŌĆÖ (the genes are located in CNV regions) and ŌĆśrearŌĆÖ (the genes span the rear part of the CNV regions), these CNVs will affect the transcription start site of the position-linked gene. Thus, inside and rear CNVs are expected to affect gene expression levels significantly. In other words, in the former two cases the expression of genes linked with CNVs may show moderate correlation with copy number changes, whereas in the latter two cases the expression of genes linked with CNVs may exhibit strong correlation with copy number changes. However, in this study, the correlation between the gene expression levels and copy number changes was not marked. Gene expression patterns before and after exercise were analyzed by box plot (Figure 1 and Supplementary Figures 2 to 4) and showed no consistent trend based on copy number changes.
Moreover, a set of individual linear regression lines calculated for single pairs of CNVs and associated genes did not reveal a consistent trend, and the gene expression slope did not show a significant difference in terms of an increasing or decreasing pattern according to copy number changes (Figure 2 and Supplementary Table 1). These results indicate that the CNVs of deletion calls have little relationship with genome-wide expression in the racing horse. This little relationship of the CNVs to gene expression does not agree with a previous study in mouse (Henrichsen et al., 2009b), which reported a moderate correlation between gene copy number and expression. However, our study did not show a significant correlation between gene copy number and expression in the racing horse. This may be due to the CNV identification method, as the copy number was measured in a relative way using a population-based method instead of the individual-based method used in the mouse study. However, in our study, GenomeSTRiP uses both population-level concepts (e.g., average read depth) and the technical features of sequence data of each individual sample such as breakpoint-spanning reads that reflect structural variation (Handsaker et al., 2011; Mills et al., 2011). This unique approach may have contributed to the difference. It is also possible that the difference is due to the gene expression estimate based on RNA sequencing being more sensitive than that of an expression array. Further, the results may differ because the gene copy number and expression data set was only half that of mouse because we only have CNVs of deletion calls, and because our CNV status was clearly presented by allele deletion information. Moreover, we used expression data sets from four horses, whereas the mouse study was based on expression data in only one strain with extreme homozygosity, which may have made identification of common tendency in horse difficult. For example, there is a correlation between gene copy number status and expression if only CNVs of the ŌĆścoverŌĆÖ group in the skeletal muscle tissue of horse 1 are considered (Figure 1), or CNVs of the ŌĆśinsideŌĆÖ group in blood are considered (Supplementary Figure 2). Also, the simple relationship between CNVs and gene expression could be due to strong tissue-specific transcriptional regulation (Subramanian et al., 2005) and strong individual-specific transcriptional regulation due to differences in individual physical activity and nutritional status (Cobb et al., 2005) or by epigenetic regulation by differential genomic imprinting (Jaenisch and Bird, 2003).
From the linear regression results in Supplementary Table 1, it appears that gene expression levels increased or decreased according to allele deletion at CNV regions by chance. One third of CNV linked genes showed increased expression, and one-third showed increased expression, according to copy number. Such observations are in line with findings that genes can show both increased (Somerville et al., 2005; McCarroll and Altshuler, 2007) or decreased (Lee et al., 2006; Guryev et al., 2008) expression with increasing copy number. These patterns of partial or no correlation observed overall suggest either dosage compensation mechanisms or the incomplete inclusion of regulatory elements in the deletion events (Henrichsen et al., 2009a).
The genes showing consistent tendency in the four sampling conditions (blood, skeletal muscle, before and after exercise) were identified and are listed in Supplementary Table 2. In the ŌĆścover negativeŌĆÖ group, in which the genes cover the CNV region and show decreased gene expression patterns according to allele deletions at the CNV region, it appears that those genes are involved mainly in membrane structure or cytoskeleton. In the DAVID enrichment test, the KEGG pathway term ŌĆścell adhesion moleculesŌĆÖ was enriched, which includes CNTN1 and PTPRM genes. DIAPH3 and PAK7 genes (Supplementary Figure 1a) are involved in the ŌĆśregulation of actin cytoskeletonŌĆÖ term of the KEGG pathway. The ANK1 gene encodes Ankyrins, which are a family of proteins that link membrane proteins to the cytoskeleton (Chorzalska et al., 2010), and the APBB1IP gene functions in signal transduction from Ras activation to cytoskeleton remodeling (Inagaki et al., 2003). These cellular-structure-related genes were not likely under tight transcriptional regulation, which could be due to the buffering effect of those genes on dosage alteration.
In the ŌĆścover positiveŌĆÖ group, in which the genes cover the CNV region and show increased expression patterns according to allele deletion at the CNV region, there were two disease related KEGG pathway terms including two genes, PARK2 for ParkinsonŌĆÖs disease and HLA-DQB1 (DQB gene in horse) (Supplementary Figure 1b) for immune disease. PARK2 encodes the Parkin protein which plays a role in the cellular machinery that degrades unneeded proteins by ubiquitin tagging (Dawson and Dawson, 2010). PARK2 haploinsufficiency is a risk factor for ParkinsonŌĆÖs disease, and deletions within PARK2 are associated with its development (Pankratz et al., 2011). HLA-DQB1, a gene in the human leukocyte antigen (HLA) region, has an important association with autoimmune disease, and a HLA-DQB1 polymorphism was reported to be associated with susceptibility to systemic lupus erythematosus (Casta├▒o-Rodr├Łguez et al., 2008). A similar pattern was observed in DEFA3, the human ╬▒-defensin gene that plays an important role in the innate immune system; DEFA3 expression was not correlated with genomic copy number (Aldred et al., 2005). Higher expression levels may compensate for lower specific activity. Also, dosage mutation by CNVs could trigger the overexpression of specific genes. However, overexpression according to deletions in CNV regions has not been investigated extensively.
In our CNV validation, we found 77% concordance between the GenomeSTRiP and PCR results. Previous validation reports of GenomeSTRiP prediction showed 83% concordance (5,833 of 7,015 CNVs validated by PCR, array data or breakpoint assembly) (Handsaker et al., 2011) and 87% concordance (14 of 16 CNVs validated by quantitative PCR) (Xi et al., 2011). In comparison, the accuracy of CNV prediction by GenomeSTRiP was moderate.
Due to our limited sample size, the CNV set may include a minor fraction of false positive error. Thus, a large sample size is required, which was not possible in this study. Besides, a more complete set of CNVsŌĆöincluding duplication or insertion call setsŌĆöis needed for a more accurate assessment of the impact of CNVs on gene expression. However, we believe that our analyses represent a foundation for further studies of CNVs that affect gene expression.
In summary, we did not observe a clear and consistent relationship between the deletion status of CNVs and gene expression levels before and after exercise in blood and muscle. However, we found some pairs of CNVs and associated genes that indicated relationships with gene expression levels: a positive relationship with genes responsible for membrane structure or cytoskeleton and a negative relationship with genes involved in disease. These observations indicate that copy number deletion has little impact on gene expression levels in racehorses. Our study provides new information regarding the relationship between CNVs and global gene expression in horse. It also motivates further work, such as unraveling the molecular basis of the tight gene expression regulation in spite of allele deletion at CNV regions and the evolutionary mechanism involving ancestral and recent CNVs.
 PDF Links
PDF Links PubReader
PubReader ePub Link
ePub Link Full text via DOI
Full text via DOI Full text via PMC
Full text via PMC Download Citation
Download Citation Print
Print







